
Scene extrapolation -- the idea of generating novel views by flying into a given image -- is a promising, yet challenging task. For each predicted frame, a joint inpainting and 3D refinement problem has to be solved, which is ill posed and includes a high level of ambiguity. Moreover, training data for long-range scenes is difficult to obtain and usually lacks sufficient views to infer accurate camera poses. We introduce DiffDreamer, an unsupervised framework capable of synthesizing novel views depicting a long camera trajectory while training solely on internet-collected images of nature scenes. Utilizing the stochastic nature of the guided denoising steps, we train the diffusion models to refine projected RGBD images but condition the denoising steps on multiple past and future frames for inference. We demonstrate that image-conditioned diffusion models can effectively perform long-range scene extrapolation while preserving consistency significantly better than prior GAN-based methods. DiffDreamer is a powerful and efficient solution for scene extrapolation, producing impressive results despite limited supervision. Project page: https://primecai.github.io/diffdreamer.
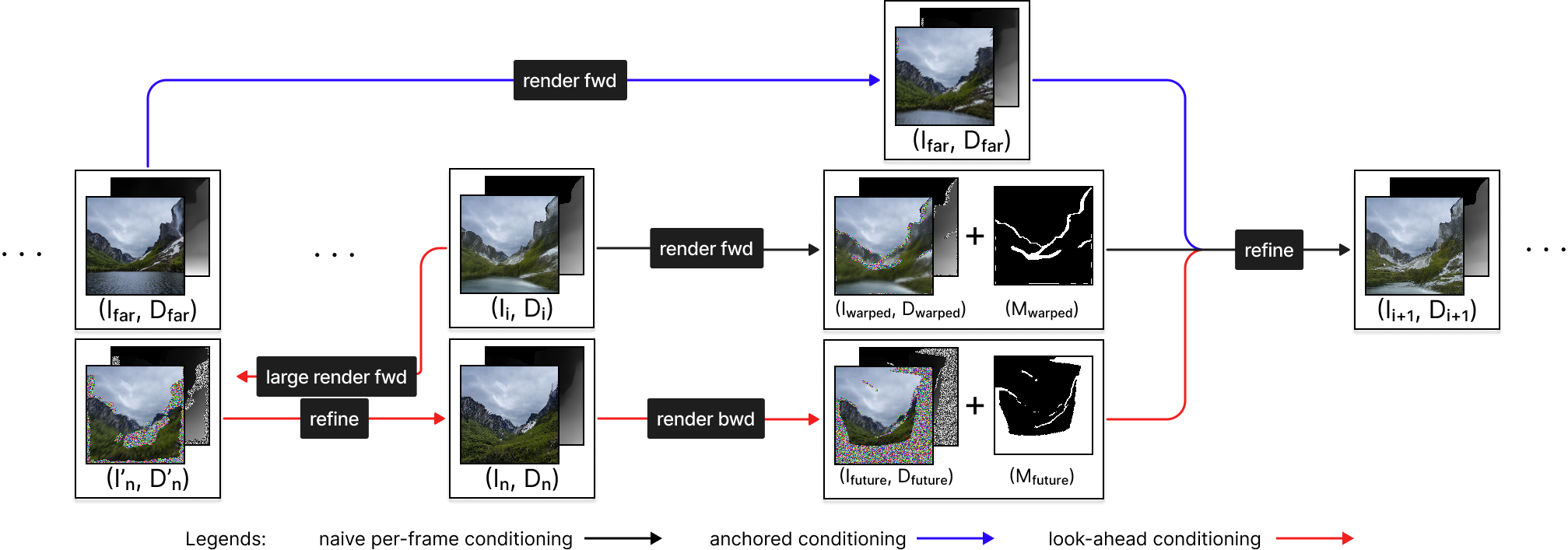
Overview of our pipeline. We train an image-conditional diffusion model to perform image-to-image refinement and inpainting given a corrupted image and its missing region mask. At inference, we perform stochastic conditioning on three conditionings: naive forward warping from the previous frame (black arrow), anchored conditioning by warping a further frame (blue arrow), and lookahead conditioning by warping a virtual future frame (red arrow). We repeat this render-refine-repeat pipeline to get sequences extrapolating a given image.
Flying into the input images.
Flying out of the input images.
@inproceedings{cai2022diffdreamer,
title = {DiffDreamer: Towards Consistent Unsupervised Single-view Scene Extrapolation with Conditional Diffusion Models},
author = {Cai, Shengqu and Chan, Eric Ryan and Peng, Songyou and Shahbazi, Mohamad and Obukhov, Anton
and Van Gool, Luc and Wetzstein, Gordon},
booktitle = {ICCV},
year = {2023}
}