|
I'm a CS PhD student at Stanford University,
advised by Prof. Gordon Wetzstein and Prof. Leonidas Guibas.
I am partly supported by a Stanford School of Engineering Fellowship.
Before Stanford, I was a CS master student at ETH Zürich
supervised by Prof. Luc Van Gool.
I obtained my Bachelor degree in Computer Science with first honour from King's College London in United Kingdom, where I spent some time working on information theory.
I work on long context and generative models, hoping they can one day forward simulate the future, and reverse engineer the past. |

|
|
Email CV Google Scholar Semantic Scholar GitHub Twitter LinkedIn |
|
News
|
BlogRandom longer-form thoughts on research, scaling, world models, and whatever else feels worth writing down. |
Publications* and † indicate equal contribution |

|
Shengqu Cai, Weili Nie*, Chao Liu*, Julius Berner, Lvmin Zhang, Nanye Ma, Hansheng Chen, Maneesh Agrawala, Leonidas Guibas, Gordon Wetzstein, Arash Vahdat In ICML 2026 [Project Page][Paper] Decouple local realism and long-range coherence for fast long-video generation by combining mode-seeking teacher distillation with mean-seeking long-video supervision. |

|
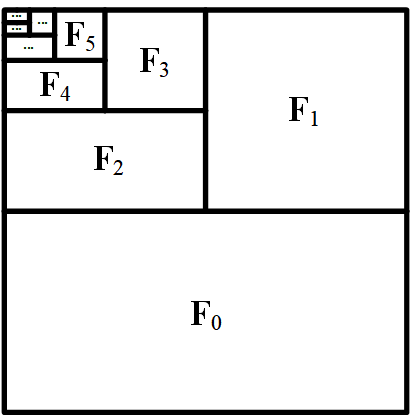
Shengqu Cai, Ceyuan Yang, Lvmin Zhang, Yuwei Guo, Junfei Xiao, Ziyan Yang, Yinghao Xu, Zhenheng Yang, Alan Yuille, Leonidas Guibas, Maneesh Agrawala, Lu Jiang, Gordon Wetzstein In ICLR 2026 [Project Page][Paper] Learnable sparse attention routing enables minute-long context with short-video cost, pruning most token pairs while preserving minute-long context coherence. |
|
Lvmin Zhang, Shengqu Cai, Muyang Li, Gordon Wetzstein, Maneesh Agrawala In NeurIPS 2025 (Spotlight) [Project Page] [Paper] [Code] Frame context packing for next-frame prediction enables longer contexts within fixed sequence budgets, with drift prevention to reduce error accumulation. |

|
Yiming Wang, Qihang Zhang*, Shengqu Cai*, Tong Wu†, Jan Ackermann†, Zhengfei Kuang†, Yang Zheng†, Frano Rajič†, Siyu Tang, Gordon Wetzstein In CVPR 2026 [Project Page][Paper] Purely implicit time- and camera-controlled 4D video diffusion that enables decoupled control over world time and camera pose (bullet-time effects). |

|
Linxi Xie*, Lisong C. Sun*, Ashley Neall, Tong Wu, Shengqu Cai, Gordon Wetzstein In CVPR Findings 2026 [Project Page] [Paper] Interactive human-centric video world simulation conditioned on tracked head pose and joint-level hand poses. |

|
Shengqu Cai, Eric Ryan Chan, Yunzhi Zhang, Leonidas Guibas, Jiajun Wu, Gordon Wetzstein In CVPR 2025 [Project Page][Paper][Code][Demo] Training-free customized image generation model that scales to any instance and any context. |
|
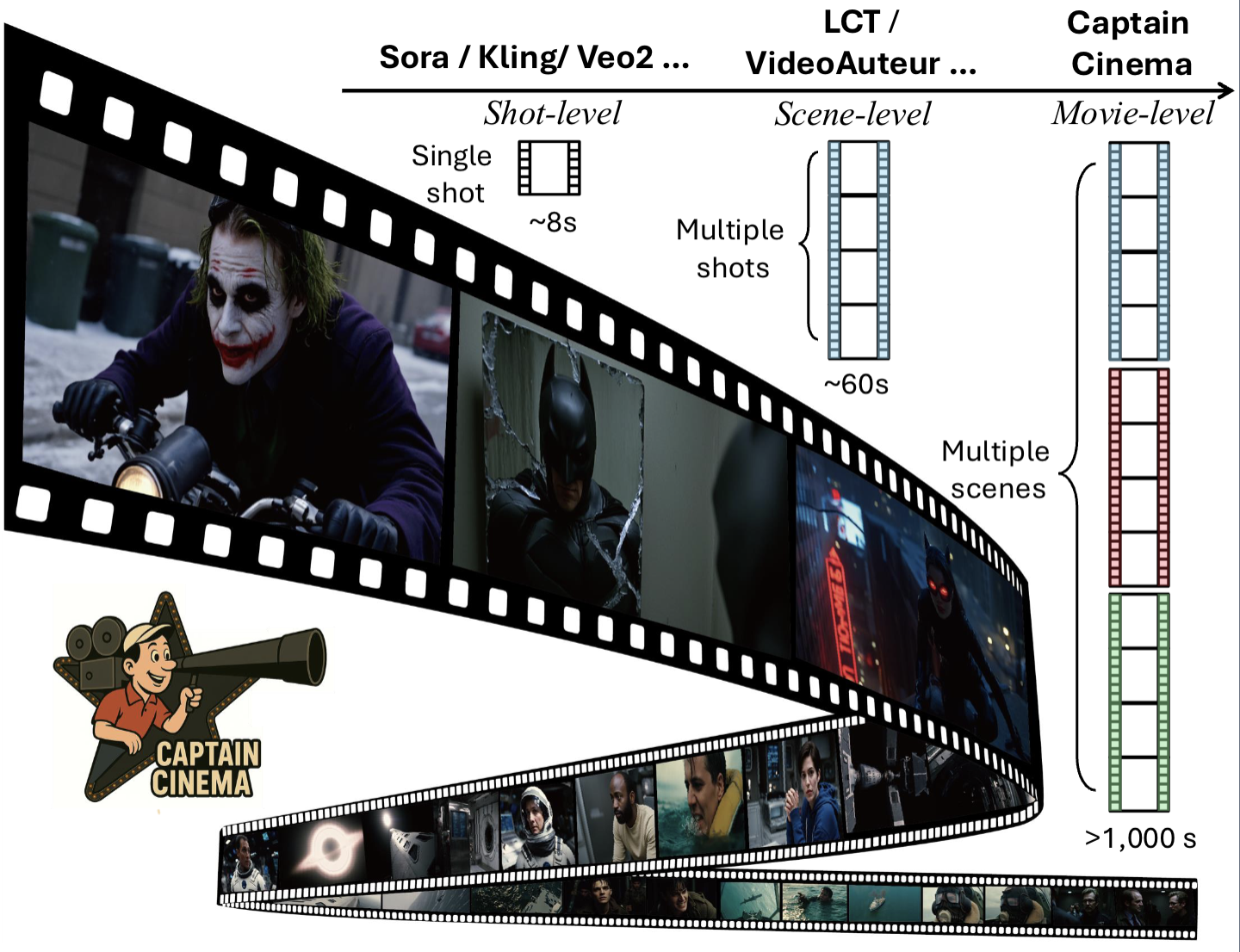
Junfei Xiao, Ceyuan Yang, Lvmin Zhang, Shengqu Cai, Yang Zhao, Yuwei Guo, Gordon Wetzstein, Maneesh Agrawala, Alan Yuille, Lu Jiang In ICLR 2026 [Project Page] [Paper] Top-down keyframe planning with bottom-up long-context video synthesis, using interleaved training to adapt MM-DiT for stable and efficient multi-scene generation. |

|
Jan Ackermann, Jonas Kulhanek, Shengqu Cai, Haofei Xu, Marc Pollefeys, Gordon Wetzstein, Leonidas Guibas, Songyou Peng In ICCV 2025 [Project Page][Paper][Code] Efficiently updates Gaussian splatting-based 3D scene reconstructions from incremental images via change detection and local optimization. |

|
Di Chang*, Mingdeng Cao*, Yichun Shi, Bo Liu, Shengqu Cai, Shijie Zhou, Weilin Huang, Gordon Wetzstein, Mohammad Soleymani, Peng Wang In arXiv 2025 [Project Page] [Paper] [Code] Large-scale benchmark and baseline for instruction-guided image editing with complex non-rigid motions such as viewpoint changes, articulations, and deformations. |

|
Liyuan Zhu, Shengqu Cai*, Shengyu Huang*, Gordon Wetzstein, Naji Khosravan, Iro Armeni In SIGGRAPH 2025 [Project Page][Paper][Code] Scene-level appearance transfer from a single style image to multi-view real-world scenes with semantic correspondences. |
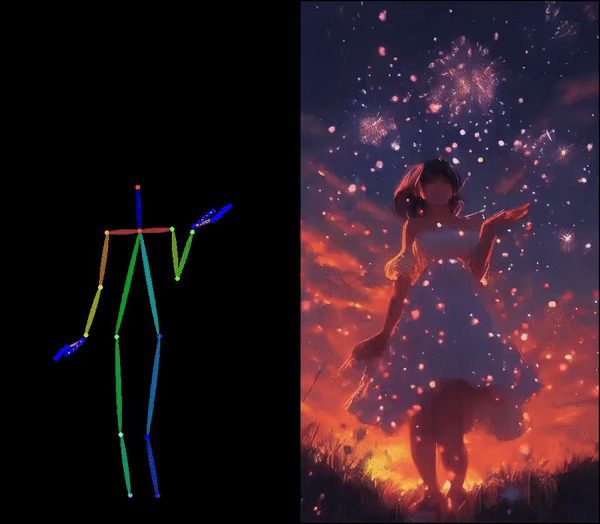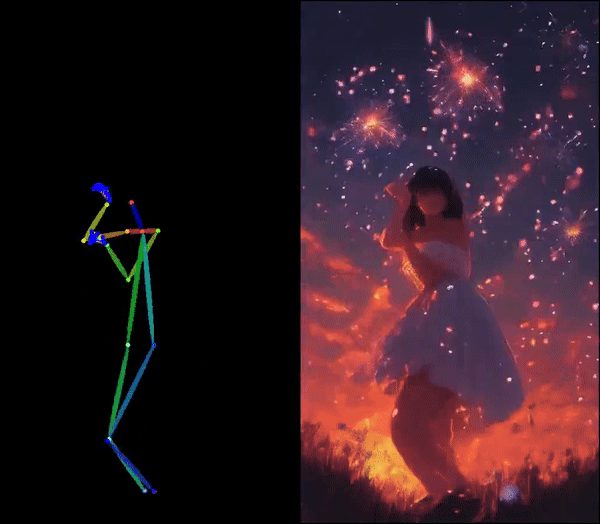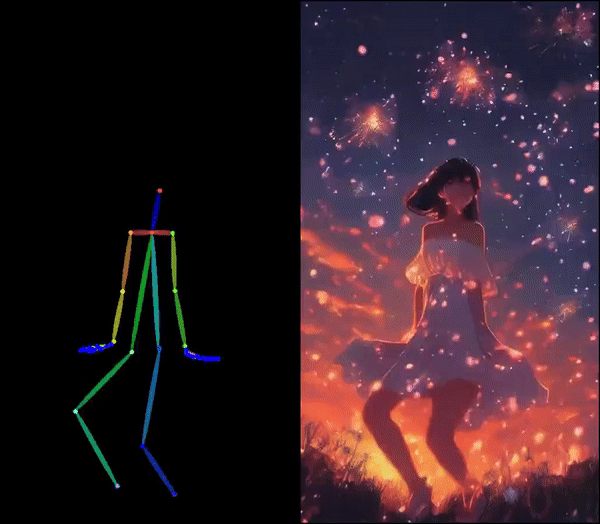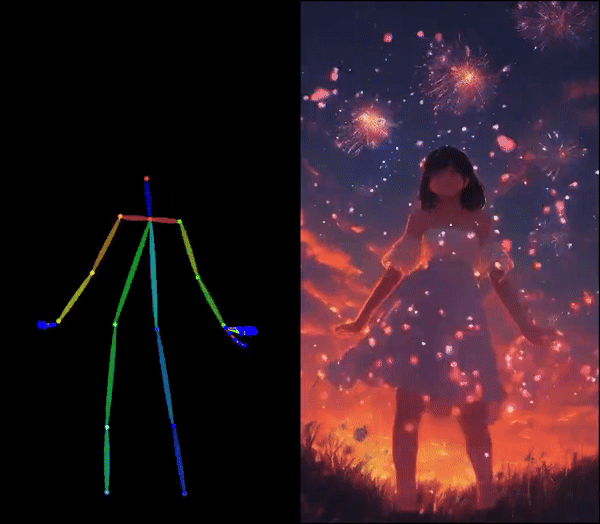
|
Di Chang, Hongyi Xu*, You Xie*, Yipeng Gao*, Zhengfei Kuang*, Shengqu Cai*, Chenxu Zhang*, Guoxian Song, Chao Wang, Yichun Shi, Zeyuan Chen, Shijie Zhou, Linjie Luo, Gordon Wetzstein, Mohammad Soleymani In CVPR 2025 (Highlight) [Project Page][Paper][Code] Human image animation using facial expressions and body movements derived from a driving video. |

|
Zhengfei Kuang*, Shengqu Cai*, Hao He, Yinghao Xu, Hongsheng Li, Leonidas Guibas, Gordon Wetzstein In NeurIPS 2024 [Project Page][Paper][Code] Multi-view/multi-trajectory generation of videos sharing the same underlying content and dynamics. |

|
Jihyeon Je*, Jiayi Liu*, Guandao Yang*, Boyang Deng*, Shengqu Cai, Gordon Wetzstein, Or Litany, Leonidas Guibas In SIGGRAPH Asia 2024 [Project Page][Paper] Render low fidelity animated mesh directly into animation using pre-trained 2D diffusion models, without the need of any further training/distillation. |
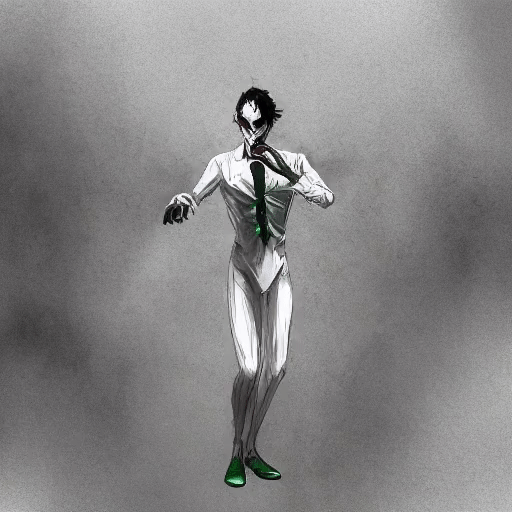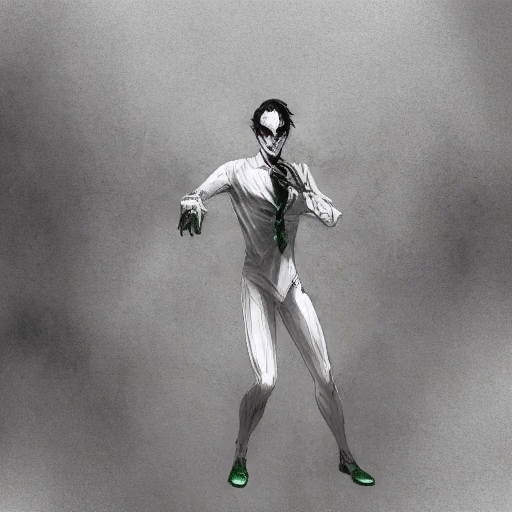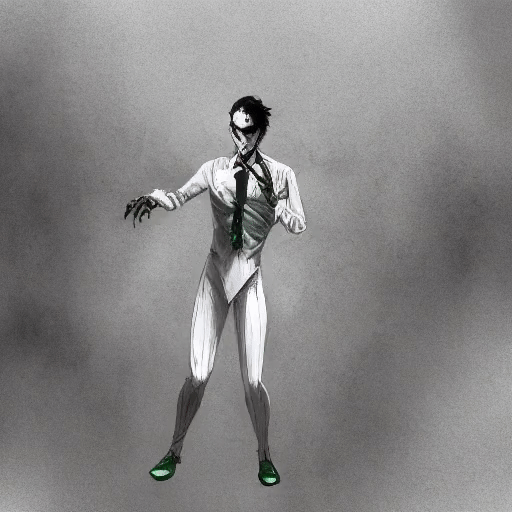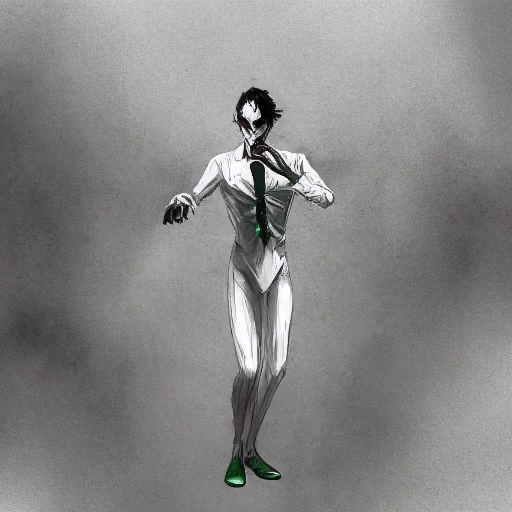
|
Shengqu Cai, Duygu Ceylan*, Matheus Gadelha*, Chun-Hao Paul Huang, Tuanfeng Y. Wang, Gordon Wetzstein In CVPR 2024 [Project Page][Paper] Render low fidelity animated mesh directly into animation using pre-trained 2D diffusion models, without the need of any further training/distillation. |

|
Shengqu Cai, Eric Ryan Chan, Songyou Peng, Mohamad Shahbazi, Anton Obukhov, Luc Van Gool, Gordon Wetzstein In ICCV 2023 [Project Page][Paper][Code] A diffusion-model based unsupervised framework capable of synthesizing novel views depicting a long camera trajectory flying into an input image. |

|
Shengqu Cai, Anton Obukhov, Dengxin Dai, Luc Van Gool In CVPR 2022 [Paper][Code] 3D-free unsupervised Single view NeRF-based novel view synthesis via conditional NeRF-GAN training and inversion. |
Industry Experience
|



Teaching
|

Misc
|